Depuis la sortie du modèle de langage basé sur l’intelligence artificielle ChatGPT, développé par OpenAI, l’engouement pour les applications basées sur le traitement du langage naturel n’a cessé de croître. Toutefois, un nouveau concurrent sérieux fait son entrée sur le marché : Falcon. Développé en tant que projet Open Source, Falcon offre une alternative prometteuse à ChatGPT, suscitant un intérêt croissant dans la communauté de l’IA et du NLP (Natural Language Processing). Dans cet article, nous explorerons les caractéristiques clés de Falcon, et examinerons une implémentation rapide.
Le nouveau modèle Falcon arrive sur Hugging Face
Le 5 juin 2023, un nouveau « Language Model » totalement Open Source a été mis à la disposition de la communauté sur Hugging Face par le laboratoire Technology Innovation Institute d’Abu Dhabi (cf https://huggingface.co/blog/falcon). Ce qui est important à noter est que ce nouveau modèle est en capacité à rivaliser avec les modèles fermés comme ChatGPT avec un nombre de paramètres bien moindre et donc une mise en production beaucoup plus simple et moins coûteuse.
La famille Falcon est composée de deux modèles de base : Falcon-40B et son petit frère Falcon-7B. Le modèle Falcon-40B, avec ses 40 milliards de paramètres, occupe actuellement la première place du classement Open LLM Leaderboard, tandis que le modèle Falcon-7B est le meilleur de sa catégorie en termes de performances.

Falcon-40B nécessite environ 90 Go de mémoire GPU, ce qui est considérable, mais moins que LLaMA-65B, que Falcon surpasse. En revanche, Falcon-7B n’a besoin que d’environ 15 Go, ce qui le rend accessible pour l’inférence et le fine-tuning même sur du matériel grand public.
Le laboratoire TII a également mis à disposition des versions « instructives » des modèles, Falcon-7B-Instruct et Falcon-40B-Instruct. Ces variantes expérimentales ont été affinées sur des instructions et des données conversationnelles, ce qui les rend plus adaptées aux tâches de type assistant populaire. Si vous souhaitez simplement jouer rapidement avec les modèles, ce sont les meilleures options. Il est également possible de créer votre propre version instructive personnalisée, en vous basant sur la multitude d’ensembles de données construits par la communauté, notamment sur Hugging Face.
Falcon-7B et Falcon-40B ont été entraînés sur respectivement 1,5 billion et 1 billion de tokens, conformément aux modèles modernes optimisés pour l’inférence. L’ingrédient clé de la haute qualité des modèles Falcon réside dans leurs données d’entraînement, principalement basées (>80 %) sur RefinedWeb, un nouvel ensemble de données web massif basé sur CommonCrawl. Au lieu de rassembler des sources sélectionnées éparpillées, TII s’est concentré sur l’augmentation d’échelle et l’amélioration de la qualité des données web, en exploitant la déduplication à grande échelle et un filtrage strict pour atteindre la qualité des autres corpus. Les modèles Falcon incluent toujours quelques sources sélectionnées dans leur entraînement (comme des données conversationnelles de Reddit), mais significativement moins que ce qui est courant pour des modèles de langage de pointe tels que GPT-3 ou PaLM. TII a publié publiquement un extrait de 600 milliards de tokens de RefinedWeb que la communauté peut utiliser dans ses propres modèles de langage de grande envergure !
Expérimentation rapide
Pour tester ce modèle, nous avons utilisé 🦜🔗LangChain, HuggingFace avec une interface via chainit pour interagir plus facilement via un navigateur. Le test a été conduit sur un MacBook Pro M2 avec le modèle falcon-7b-instruct.
Une fois les différentes librairies installées, le code est minimal:
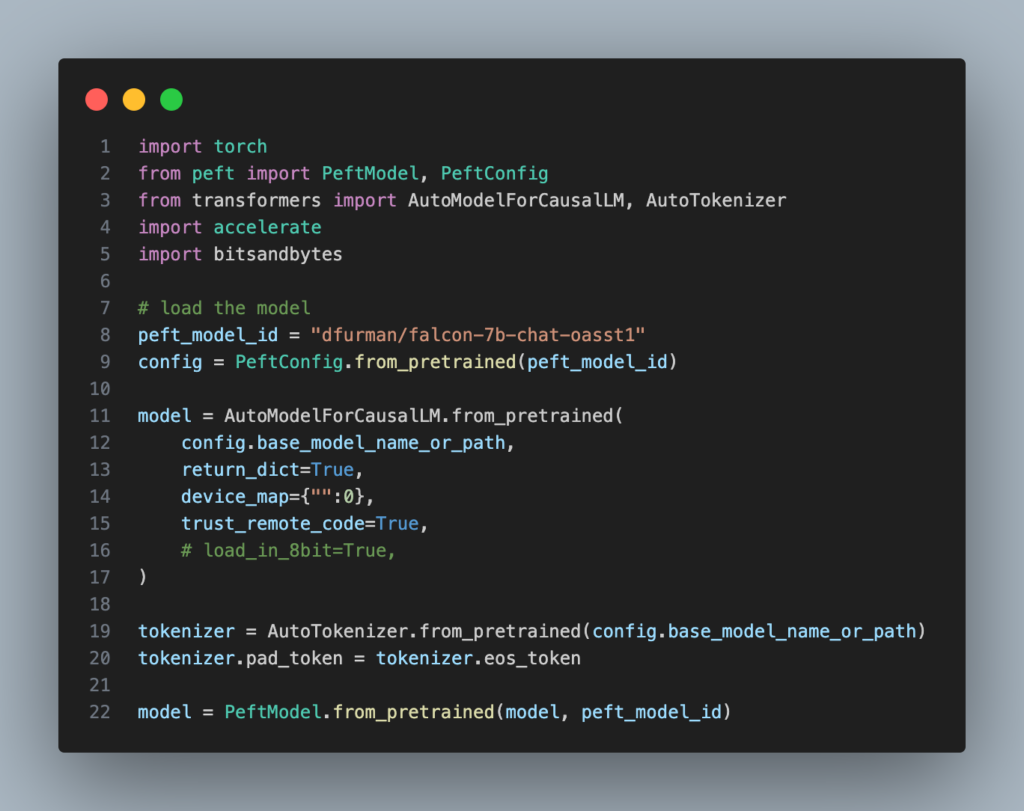
Et le lancement de l’interface se fait simplement en exécutant :
chainlit run app.py
Quelques retours d’expérience
Sur un MacBook Pro M2, sans travail particulier, l’usage est fluide. Cela indique donc qu’il est possible d’espérer de rapidement voir des applications se développer autour de ce nouveau modèle.
Les modèles Falcon ont été entrainés en anglais et en français, cependant l’anglais semble être la langue qui réagit le mieux lors des tests.
Le modèle avec plus de paramètre (falcon-40b) n’a pas été testé mais devrait être capable de donner des résultats encore plus pertinents.
Conclusion
Falcon, en tant que modèle Open Source, représente une alternative intéressante à ChatGPT. Avec sa flexibilité, sa personnalisation et sa nature collaborative, Falcon offre de nouvelles perspectives pour les applications basées sur le traitement du langage naturel. Surtout, il garanti la possibilité de faire tourner le modèle directement dans son infrastructure ce qui présente comme avantage une meilleure maitrise des coûts et un non partage de ses données sensible. Les modèles Open Source comme alternative à ChatGPT semblent tenir la corde pour le moment, l’avenir n’est donc pas écrit


